正確的建立索引,在我們select資料時,MySQL會自動尋找最佳途徑,提高操作效能,MySQL還提供myisam儲存引擎fulltext索引,能夠用於全文搜尋,但只限於char、varchar與text欄位。
最適當的索引列就是我們最常使用where語句來篩選的欄位,而不是想要select的欄位,在考慮建立索引時,也要看看欄位值的分布大小,如果那個欄位值只包含「男」、「女」,這樣建立索引就沒有意義,因為不管怎麼樣查詢出來的都大約是一半的值。
然而也不是索引建立越多越好,索引也會占用硬碟空間,可能造成IO的問題,修改表的定義時,索引也會需要更新,而且在每次MySQL執行查詢時,都會先考慮所有索引,尋找最適合的,有可能會造成更多的效能問題。
比較特別的是Innodb儲存引擎存在兩種不同的索引,一種是cluster index,當建立表時沒有自己建立primary key(主鍵),或是unique(唯一值)將會自己產生隱藏索引(GEN_CLUST_INDEX),增加查詢效率,另一種是和其他除引擎存放相同的普通Btree索引,稱為secondary Index。
下圖做個比較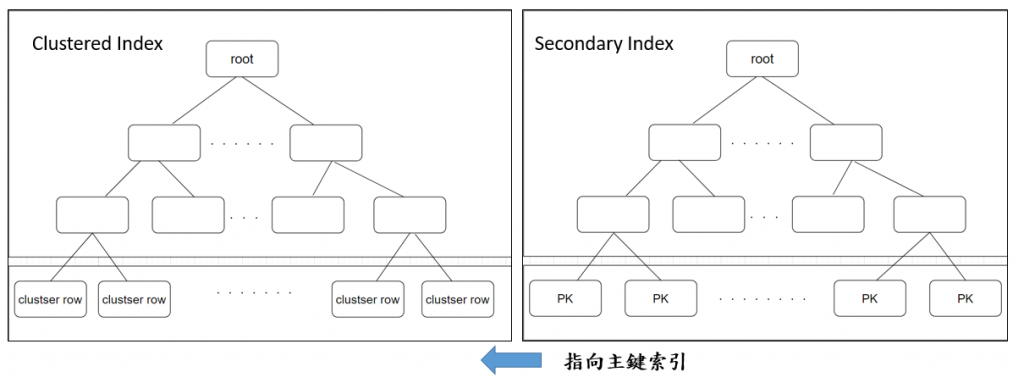
左方為clustered形式存放索引,右方為Secondary index。
兩個不同的是在clustered的leaf nodes存放的是表的實際資料,不只是主鍵欄位值,而是包含了其他欄位的資料,Secondary則只是存放索引鍵訊息與innodb的主鍵值。
以下我們用測試表來建立索引!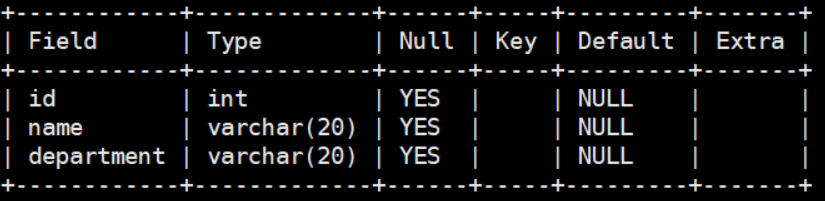
我們用ID來建立索引
指令如下:
Create index [index_name] on table_name;
mysql> create index id_index on t1(id);
查看index
show index from [table_name]
mysql> show index from t1\G
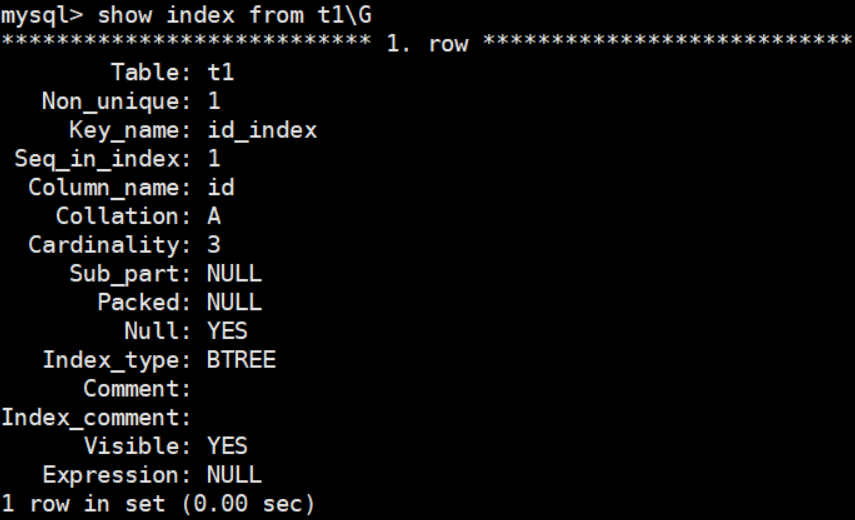
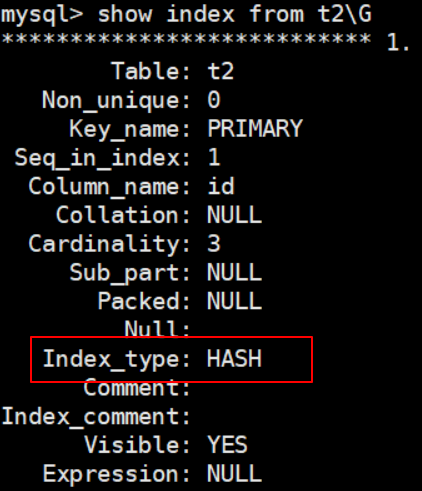
兩種不同類型的索引有著不同的適用範圍,hash索引效率非常高,不需要像Btree索引需要從根節點開始搜尋,但因為hash索引有些限制,所以現在innodb與myisam都使用btree,只有memory引擎預設是HASH。
Hash索引只能使用=或是in和<=>來查詢,無法使用範圍查詢,像是like或是between,也無法用來避免數據排序操作。
以下測試hash索引與btree索引的執行計畫。
建立相同的表使用不同的索引類型。
mysql> create table t1 (id int,name varchar(20),primary key (id) using btree);
mysql> insert into t1 values(1,'andy'),(2,'nini'),(3,'chichi');
mysql> show index from t1\G
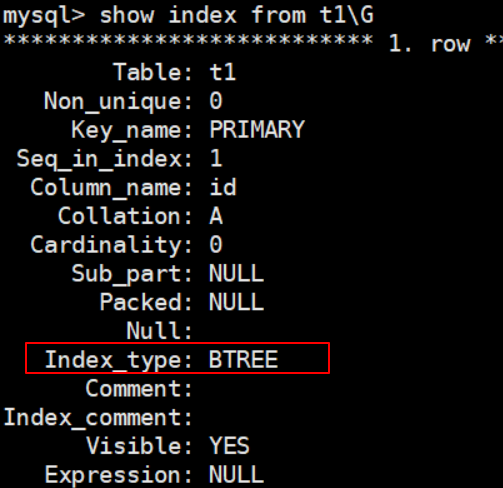
mysql> create table t2 (id int,name varchar(20),primary key(id) using hash)engine=memory;
mysql> insert into t2 values(1,'andy'),(2,'nini'),(3,'chichi');
mysql> show index from t2\G
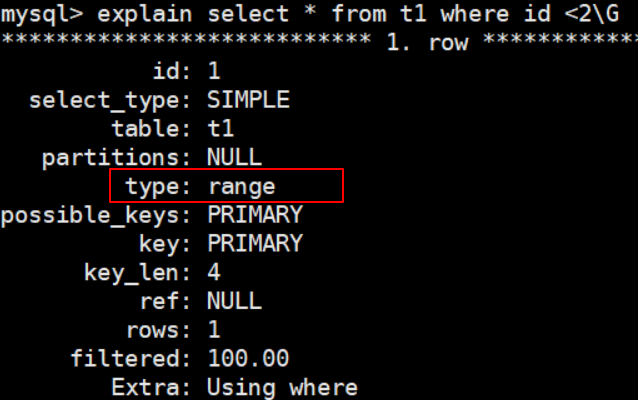
使用範圍查詢
mysql> explain select * from t1 where id <2\G
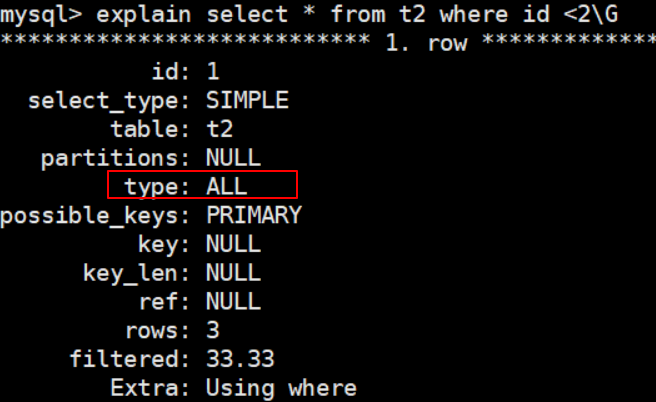
使用hash類型會是全文搜尋。
mysql> explain select * from t2 where id <2\G
現在有沒有比較知道索引是甚麼了呢?
參考網站:https://kknews.cc/zh-tw/code/mbezy66.html

